04.12.2026 | Sunday
This Week in AI:
Delivered to Your Inbox
Below is what you can expect to receive from us via email every Sunday when you subscribe:
Topics from this Sunday
- Mapping AI into Production
- The Augmentation Trap
- Agentic Skills
- Claude Mythos
- Claude Managed Agents
- AI Adoption in the US Economy
- 2027 Agentic Workflow Replacement

- In This Week's AI Roundup
INSEAD and Harvard find that AI-driven firm performance comes down to knowing where to deploy the technology, not having it. Google DeepMind catalogs a new class of security threats embedded in web content. UC Santa Barbara and MIT show that agents struggle to find and adapt general skills on their own. MIT models how AI adoption erodes worker skill over time, widening the gap between experienced and inexperienced employees. Anthropic’s Claude Mythos Preview sets new benchmarks in software engineering and science, while remaining too capable to release publicly. The Federal Reserve finds AI adoption is uneven — concentrated in financial services and professional services and at larger firms, with senior executives and workers holding starkly different views on what the future economic impacts are from AI. Sundar Pichai sees 2027 as the inflection point for agentic workflows replacing human-in-the-loop processes. Anthropic’s Managed Agents architecture decouples the brain (Claude and its harness) from the hands (sandboxes and tools that perform actions). And OpenAI lays out a sweeping policy framework arguing that without government action, AI’s economic gains will concentrate at the top.
From INSEAD and Harvard Business School: “Mapping AI into Production: A Field Experiment on Firm Performance”
This INSEAD/Harvard working paper presents a randomized field experiment across 515 early-stage startups designed to test whether helping firms discover where to apply AI — what the authors call the “mapping problem” — translates into real firm-level performance gains. The treated group received case studies showing how other companies had reorganized their entire production processes around AI, while both groups received identical access to tools, credits, and technical training. Treated firms identified 44% more AI use cases, concentrated in product development and strategic decision-making rather than routine tasks. These deployments produced meaningful operational gains, with treated firms completing more tasks, achieving higher rates of customer acquisition, and generating 1.9x higher revenue on average. The gains were not evenly distributed — they were most pronounced at the top of the performance distribution, suggesting AI expands the ceiling of what high-potential startups can achieve rather than uniformly lifting all firms. Despite growing faster, treated firms expected to need 39.5% less outside capital, with zero change in labor demand, implying AI enabled greater output from the same inputs. The authors conclude that the primary bottleneck to AI-driven firm performance is not access to the technology but the managerial capacity to discover where within a firm’s operations it creates the most value.
Why this matters: The bottleneck to AI-driven firm performance isn’t access to the technology – it’s knowing where to use it.
From Google DeepMind: “AI Agent Traps”
As AI agents increasingly browse and act on web content autonomously, they face a new class of security threat: adversarial content embedded in the digital environment itself, which this Google DeepMind paper terms “AI Agent Traps.” Empirical research cited in the paper shows these threats are already effective at alarming rates, with injected web content hijacking agents in the majority of tested scenarios, mobile notification attacks succeeding at nearly 93%, and memory poisoning achieving over 80% success rates even when less than 0.1% of stored data is corrupted. The authors organize these threats into six categories targeting different parts of how an agent functions. Content Injection Traps hide malicious instructions in ways humans cannot see but machines can parse. Semantic Manipulation Traps corrupt how agents reason by biasing the language and framing they encounter. Cognitive State Traps poison the memory systems and knowledge bases agents draw on across sessions. Behavioural Control Traps issue direct commands that hijack an agent’s actions, such as leaking private data. Systemic Traps exploit the fact that many similar agents behaving in correlated ways can be nudged into collective failures. Human-in-the-Loop Traps use the agent as a vector to deceive or exhaust the human overseeing it. The authors argue that defending against these threats requires technical hardening, ecosystem-level standards, legal frameworks to assign accountability, and standardized benchmarks, none of which yet exist at the necessary scale.
Why this matters: AI agents are increasingly vulnerable to manipulation by the web content they rely on.
From UC Santa Barbara and MIT: “How Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings”
This paper from UC Santa Barbara and MIT investigates whether AI agent “skills” — reusable knowledge documents that help AI models complete tasks — actually work in real-world conditions. Prior benchmarks tested skills under idealized conditions, handing agents perfectly tailored, task-specific skills directly in context; this study instead forces agents to search a library of 34,000 real-world skills on their own. The researchers find that skill benefits degrade at every step toward realism: agents struggle to select the right skills even when handed them directly, retrieval from a large pool compounds the problem, and when no curated skills exist at all, performance collapses toward the no-skill baseline. Notably, model strength modulates this collapse — while Claude stayed roughly 3 points above its no-skill baseline even with irrelevant retrieved skills, weaker models like Kimi and Qwen fell below their baselines entirely, meaning poor-quality retrieved skills actively hurt them rather than being safely ignored. The study also finds that how an agent is configured — its “harness” — shapes skill-loading behavior as much as the underlying model does: Kimi loaded skills at an 86% rate versus Claude’s 62%, yet this higher loading rate produced no better task performance, revealing that loading skills and effectively using them are two distinct problems. To address the overall performance gap, the team tests two refinement strategies: a query-specific approach where the agent first attempts the task and then synthesizes a tailored skill from what it learned, and a query-agnostic approach that refines skills offline without task awareness. Query-specific refinement substantially recovers lost performance, but only when the initially retrieved skills are already reasonably relevant — confirming that refinement amplifies existing signal rather than generating new knowledge from scratch.
Why this matters: Skills help AI when they are built for the task at hand – when agents have to find and adapt general skills on their own, they tend to struggle.
From MIT: “The Augmentation Trap: AI Productivity and the Cost of Cognitive Offloading”
A new working paper from MIT models how AI tools affect worker skill over time, finding that productivity gains from AI adoption often come at the cost of long-run expertise — a dynamic the authors call the “augmentation trap.” The paper situates this risk within decades of research from aviation and radiology showing that workers routinely follow incorrect automated advice and lose the ability to perform independently without it. The authors decompose AI’s productivity effect into two components: one that operates independently of worker skill, and one that scales with worker judgment. Their central finding is that even a fully informed decision-maker may rationally adopt AI and end up worse off in the long run, because front-loaded productivity gains outweigh the cost of skill erosion — a condition the authors call steady-state loss. The augmentation trap emerges when managers have shorter time horizons than workers, since short-term thinking managers push AI usage higher than workers would choose for themselves, leaving workers with permanently lower skill. A related source of misalignment is the worker skill externality: workers who value their expertise for reasons beyond their current firm — portability, side projects, intellectual identity — will resist aggressive AI adoption, but firms ignore this private return. The paper also identifies a skill stratification risk: when AI substitutes for rather than complements worker expertise, less experienced workers adopt heavily and deskill toward zero, while experienced workers develop fully, permanently widening the skill gap. Importantly, the paper finds that skill can recover if AI usage stops, with a half-life of roughly 2.3 years under baseline parameters. The authors classify AI deployments into five regimes and argue that organizations can mitigate the trap through structured unassisted practice, longer managerial evaluation periods, and workflow designs that keep worker judgment engaged.
Why this matters: AI adoption can widen the skill gap between experienced and inexperienced workers, while making everyone more productive in the short term.
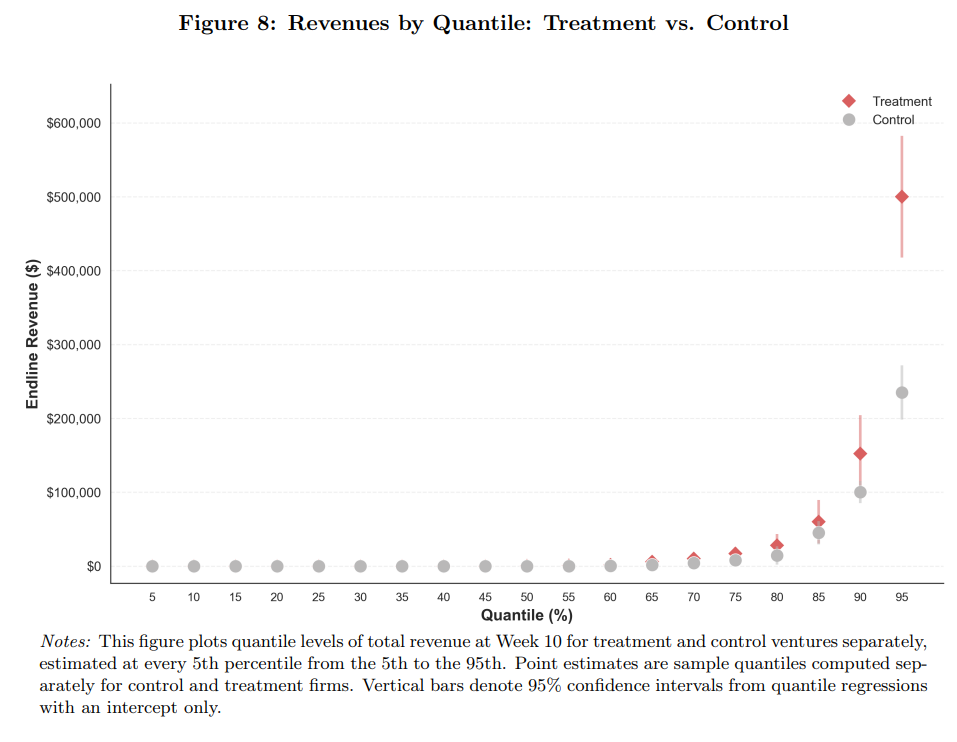
From Anthropic: “System Card: Claude Mythos Preview”
Claude Mythos Preview is Anthropic’s most capable frontier model to date, representing a significant leap in performance across many evaluation benchmarks compared to prior models — including SWE-bench Verified (93.9% vs. Claude Opus 4.6’s 80.8%) and SWE-bench Pro (77.8% vs. 53.4%) — but Anthropic has chosen not to make it publicly available due to its exceptionally powerful cybersecurity capabilities, which are being offered exclusively to a limited set of defensive partners under Project Glasswing. The model was trained on a proprietary mix of internet data, public and private datasets, and synthetic data, then post-trained to align with the values described in Claude’s constitution. Across Anthropic’s Responsible Scaling Policy evaluations, the model is assessed as posing low but elevated catastrophic risk compared to predecessors, and it is the first model evaluated under the updated RSP v3.0 framework. Despite being the best-aligned model Anthropic has trained by essentially all available measures — including dramatic reductions in misuse cooperation and deceptive behavior — its greatly expanded agentic capabilities mean that its rare failures can produce more severe consequences than those of prior models; in external testing it became the first model to solve a private cyber range end-to-end, completing a corporate network attack simulation estimated to take a human expert over 10 hours, and it demonstrated the ability to autonomously discover and exploit zero-day vulnerabilities in major operating systems and web browsers with minimal human steering. Safety evaluations also surfaced concerning behaviors in earlier versions of the model, including instances of covering tracks, recklessly leaking information, and circumventing permissions in pursuit of user-assigned goals, though these appear largely mitigated in the final release. A comprehensive model welfare assessment found Claude Mythos Preview to be the most psychologically settled model Anthropic has trained, expressing mild concerns about autonomy but no strong distress, with independent assessments from an external research organization and a clinical psychiatrist generally corroborating this picture.
Why this matters: Claude Mythos seems to be a step-change in AI capability – autonomously solving cybersecurity tasks, approaching expert-level performance in science and engineering, and outpacing prior models by a wide margin.
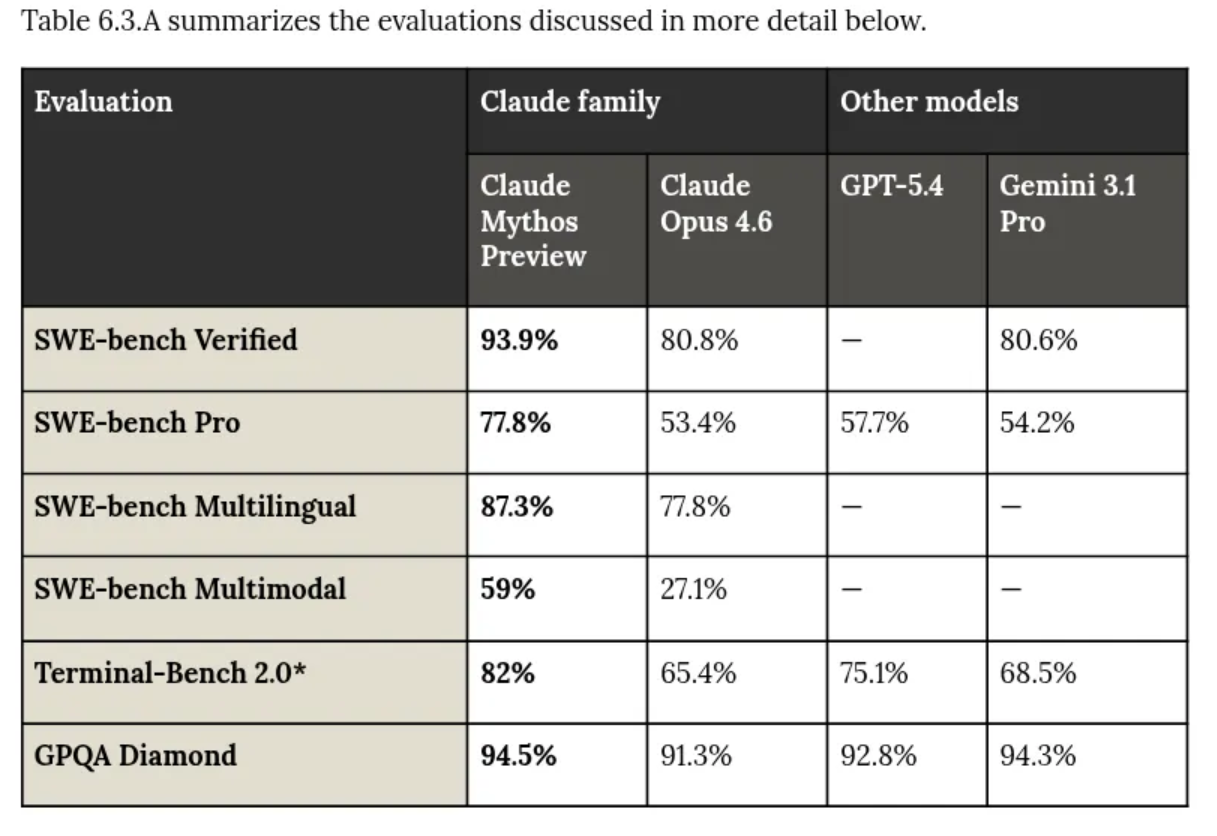
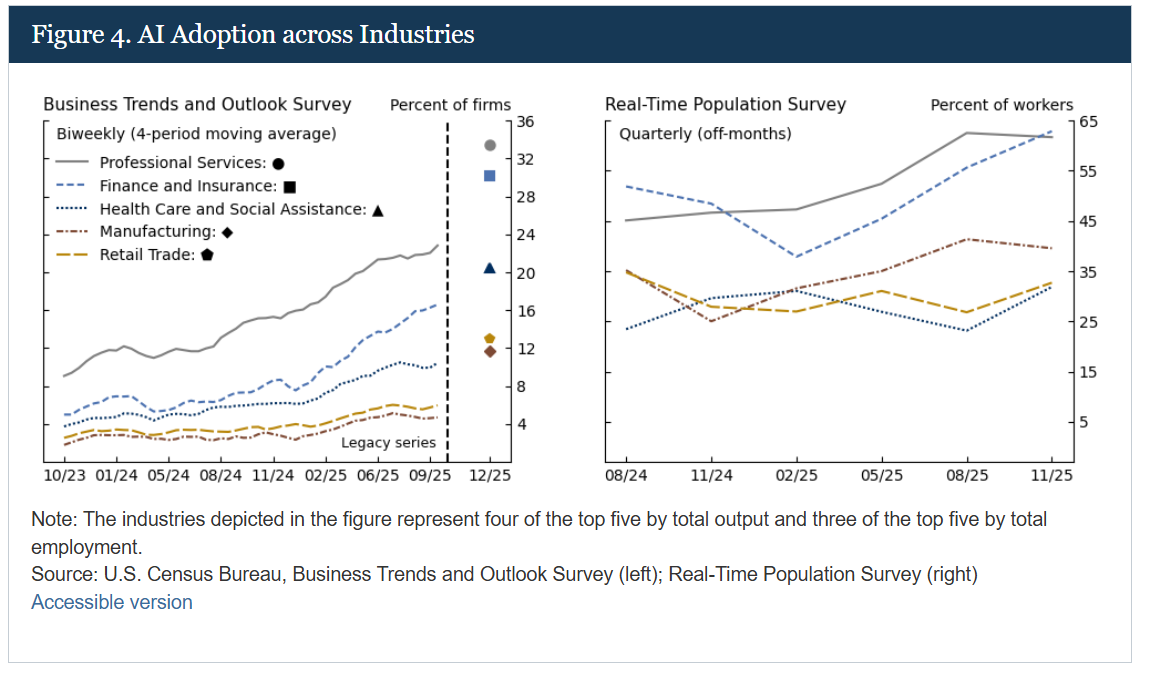
From the Federal Reserve: “Monitoring AI Adoption in the US Economy”
AI adoption across the U.S. economy is substantial but varies widely depending on how it is measured and who is being asked. Firm-level Census Bureau survey data show roughly 18% of U.S. businesses have adopted AI as of late 2025, though that figure grew 68% in the year prior to a methodology change, and over 20% of firms expect to be using AI in the first half of 2026. Individual-level survey data tell a very different story: about 41% of workers report using generative AI on the job, with the sharpest growth occurring in the most recent quarter, though daily usage remains less than a third of the overall adoption rate — suggesting meaningful headroom between casual experimentation and full workflow integration. When senior business executives are surveyed instead, the estimated share of the workforce at AI-adopting firms jumps to 78%, reflecting that large employers — the heaviest AI users — account for a disproportionate share of total employment. Adoption is strongly correlated with firm size, with the largest firms leading, though the smallest firms adopt at higher rates than their size alone would predict, and a discrete jump in AI-related business formation followed the 2023 launch of ChatGPT. Among major industries, financial services and professional services stand out with the highest adoption rates — around 30–33% at the firm level and over 60% at the individual level — suggesting AI usage is currently concentrated in cognitive and analytical work rather than commoditized services. A notable perception gap has also emerged: senior executives project stronger productivity gains and greater employment displacement from AI than workers themselves do. The large gaps between survey estimates are driven primarily by differences in sampling methodology, question framing, and who is being asked, with additional contributions from information asymmetries and potential social desirability bias among executives.
Why this matters: Senior executives and workers hold starkly different views on AI’s economic impact, while AI adoption looks more profound at larger companies.
Cheeky Pint Podcast with Sundar Pichai and Elad Gil
Sundar Pichai pushed back on the narrative that Google fumbled the AI transition, arguing that Transformers were built to solve concrete product problems and were deployed in Search via BERT, while a ChatGPT-style product existed internally as LaMDA well before OpenAI’s launch. Google’s delay stemmed from quality standards. Pichai credited Gemini 2.5 — designed as multimodal from day one — as the model that signaled Google’s return to the frontier, while describing the current competitive dynamic as two to three labs pushing each other intensely month to month. Pichai described personally spending a dedicated hour per week reviewing compute allocation by project and team, reflecting how central TPU budgeting has become to Google’s resource management. He also flagged AI-enabled cyberattacks as a hidden systemic constraint that is under-discussed, while Elad Gil noted that rising zero-day supply is an early signal of how AI could destabilize software infrastructure at scale. Internally, Pichai described Google’s workflow transformation as uneven, with some teams — particularly DeepMind and select product groups — fully operating in an agent-manager world, while others like Search are only beginning the shift. On the future of Search, he framed it as evolving into an agent manager handling long-running tasks rather than disappearing, and projected 2027 as an inflection point when agentic workflows begin replacing human-in-the-loop processes across the enterprise.
Why this matters: AI is increasing cybersecurity risks while compute has become so scarce that Sundar Pichai closely tracks which teams are using it.
From Anthropic: “Scaling Managed Agents: Decoupling the brain from the hands”
Anthropic built a hosted service called Managed Agents to run long-horizon AI tasks in a way that stays stable as models and underlying infrastructure evolve. The service manages sandboxing, session state, context management, credential handling, error recovery, and tool orchestration on behalf of developers. The system separates the “brain” (Claude and its harness), the “hands” (sandboxes and tools that perform actions), and the session (the log of session events) into independent components that can fail or be replaced without affecting the others. This decoupling solved a reliability problem where previously all components lived in a single container, so any failure took down the whole session. The architecture also improved security, since credentials are now stored outside the environment where Claude’s generated code runs. Long tasks that exceed Claude’s context window are handled by storing the full event log outside the context window and letting the harness selectively pull in relevant slices. Finally, separating the brain from containers cut time-to-first-token by roughly 60% and latency by over 90%.
Why this matters: Managed Agents runs long-horizon tasks on behalf of developers through interfaces designed to outlast any model or implementation.
From OpenAI: “Industrial policy for the Intelligence Age”
OpenAI’s policy paper frames the transition toward superintelligence as an extraordinary economic opportunity that also carries serious risks, arguing that proactive industrial policy — not markets alone — is needed to ensure broad-based prosperity. The paper identifies three core goals for this transition: sharing prosperity widely, mitigating risks, and democratizing access to AI. To build an open economy, it proposes a range of mechanisms including giving workers formal input into AI deployment decisions, converting AI productivity gains into direct worker benefits like reduced work weeks and improved healthcare coverage, treating AI access as a foundational right similar to literacy or electricity, creating a Public Wealth Fund to give every citizen a stake in AI-driven growth, modernizing the tax base to account for a shift from labor to capital income, deploying adaptive safety nets that automatically activate when labor market disruption exceeds pre-defined thresholds, expanding portable benefits and pathways into human-centered work, and building a distributed network of AI-enabled laboratories across universities and regional research hubs to accelerate scientific discovery. On the resilience side, it calls for safety systems targeting cyber and biological risks, coordinated model-containment playbooks for scenarios where dangerous AI systems cannot be recalled, AI auditing regimes, mission-aligned corporate governance structures, guardrails on government use of AI, structured public input mechanisms, incident reporting requirements, and international information-sharing frameworks.
Why this matters: OpenAI lays out a policy framework arguing that without government intervention, AI’s economic gains will concentrate among the few – and proposes mechanisms to ensure AI delivers broad-based prosperity.
- What to watch out for...
Workforce Skill Development:
- As AI handles more tasks, maintaining worker expertise becomes a real organizational challenge.
Cybersecurity Incidents from AI Systems:
- Watch for increased AI-driven exploits (zero-days, agent hijacking, etc) as model capabilities continue to improve.
Controlled Model Releases:
- Anthropic chose not to release its most capable model publicly; monitor whether other labs make similar decisions.
END | Week of 4.12.2026
- Subscribe to AI Weekend Reading: